
Compound AI Systems

Retrieval Augmented Generation (RAG) has ushered innovative ways to build around LLMs and data. Lets now see how Compound AI Systems harness the power of LLMs across multiple dimensions.

Encapsulating Compound AI Systems | Skanda Vivek
Large Language Models (LLMs) have the potential to be a game-changer in so many industries. However, during conversations with multiple folks — the observation is often that LLMs out of the box are great for general tasks like information gathering or coding — but not so much in enterprise settings. Oftentimes, responses are too generic. One complaint is that LLM responses seem too mechanistic and less authentic (too many exclamation points, for example).
So far, incorporating private data within LLM using methods like Retrieval Augmented Generation (RAG) has proved to be a way to mitigate some of these concerns.

Basic RAG | Skanda Vivek
Here, you can see the basic idea behind RAG. The RAG process starts when a user inputs a query. The model transforms this query into a numeric format, termed an embedding or vector, which can be comprehended by machines. This numeric query is then contrasted against a database of similarly encoded data in a process engineered to retrieve the most pertinent data matches. Once a match or multiple matches are identified, the system retrieves this information, converts it back into human-readable context, utilized for augmenting the content transmitted to the LLM. This permits the LLM to generate responses that are not only precise but also grounded in the most up-to-date information accessible.
Through RAG, LLMs can be tailored to specific scenarios, leading to valuable, personalized results. An example is a website chatbot that answers user queries using an LLM in combination with retrieval of the right documents. This can save valuable resources for the company and help customers who now don’t have to wait to reach someone for customer support.
However, training these systems can be hard. One issue is that these chatbots do not always return relevant documents. Another issue is hallucinations. For example, an Air Canada chatbot gave incorrect refund information to a customer and was subsequently held liable. Rather than focus on training the LLM itself, the idea behind compound AI systems is to improve task performance through system design.
Optimizing LLMs for tasks
Recently, there have been a few frameworks like DSPy that train LLMs for prompts that maximize task performance. The premise of DSPy is fascinating—what if we could train prompts in the same way we train model parameters? This idea has shown promise in academic settings , led by Stanford research. In a recent blog, I’ve also shown that it does well on representative tasks like Q&A over documents.

DSPy article | Skanda Vivek
Optimizing RAG Systems
Optimizing RAG systems requires a multi-pronged approach. The embedding model used, chunking strategy, LLM for generating responses, and context retrieval strategy — represent four large components for optimizing RAG systems.

Training RAG Systems | Goku Mohandas
Recently, there have been a lot of innovations in optimizing RAG retrieval. Here are just a few examples:
Self-RAG:
In Self-RAG, the authors develop a clever way for a fine-tuned LM (Llama2–7B and 13B) to output special tokens [Retrieval], [No Retrieval], [Relevant], [Irrelevant], [No support / Contradictory], [Partially supported], [Utility], etc. appended to LM generations to decide whether or not a context is relevant/irrelevant, the LM generated text from the context is supported or not, and the utility of the generation.
HyDE:
HyDE uses an LLM to create a hypothetical document in relation to a query. This helps during retrieval, where the hypothetical document is used to retrieve the actual documents from the database. The advantage of this is that some user queries can be quite brief, and not enough context for embedding models that thrive on rich text information. The idea here is that adding in a hypothetical “ideal” document helps retrieve more relevant documents.
Re-ranking:
Re-ranking is a simple (yet powerful) idea. First, you retrieve a large number of documents (say n=25). Next, you train a smaller re-ranker model to select the top k (say 3) documents out of the 25, and feed that as the LLM context. This is a pretty cool technique, and it makes a lot of sense to train a smaller re-ranker model for specific RAG scenarios.
Forward-Looking Active Retrieval Augmented Generation (FLARE):
FLARE is used to handle cases where you want answers to be correct and up to date — for which it makes sense to augment LLM knowledge with a real-time updated knowledge hub (the Internet). As you can see below, one solution is to combine iteratively internet searches, and LLM knowledge.

In this workflow, first, the user asks a question, and the LLM generates an initial partial sentence. This partial generation acts as a seed for an Internet search query (e.g., Joe Biden attended [X]). The result from this query is then integrated into the LLM response, and this continuous search and update process continues until the end of the generation.
Optimizing Agents And Flows
LLM Agents consist of multiple LLMs, orchestrated to plan and execute complex tasks. These can be very useful in answering complex questions like “How much did sales grow for company X between Q1 of 2024 and Q2 of 2024?” This type of user request potentially involves making multiple LLM calls, gathering multiple documents, and planning and executing these as below:

LLM Agent Prototype | NVIDIA
In addition to agents, many new results show that chaining multiple components in unique ways can result in breakthrough performance. One study shows that these three key features:
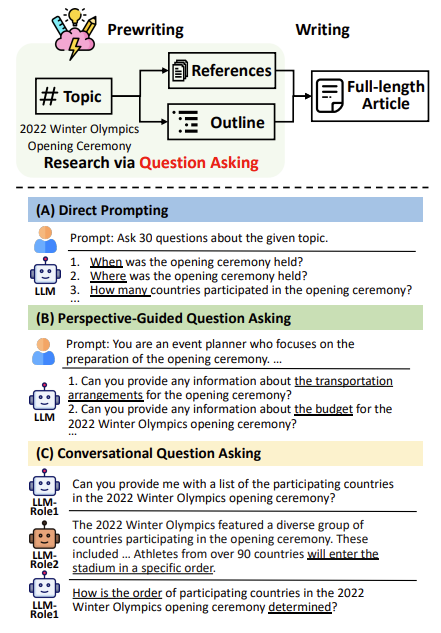
Asking key questions about a certain topic to identify information nuggets
Simulating conversations to synthesize this information
Drawing these pieces of information into an outline
leads to high-quality Wikipedia-like articles. I think this is pretty amazing, as it could lead to more tailored, human-like content through the right mix of components.
Optimizing Compound AI Systems?
As you can see, there are many aspects to optimize in compound AI systems. If you thought that optimizing RAG embeddings, chunking, retrieval, and LLM were hard enough — add multiple more dimensions, each having its own set of 1–10 levers. So is it feasible to keep track of so many parameters?
Here’s an idea: what if we treat these parameters akin to standard ML parameter choice, similar to something like gridsearchCV hyperparameters? Let’s even give this a name — AIsearchCV.
Another way to visualize this is that you want to compress any output you have into the minimal necessary inputs to reconstruct this — using the ingredients you have (here, all the aspects that make up compound AI systems). This way, you can reconstruct this text through minimal topic inputs, and the rest of the work is done automatically.

Decomposing Ideal Outputs Into Compound AI Action Space | Skanda Vivek
Takeaways
The real value of LLMs is getting AI systems to do useful tasks in specific domains. However, this involves careful system design of compound AI systems. This can often be overwhelming due to the amount of new work in this space, and the slowly growing number of dimensions to optimize. It is slowly becoming clear that this is necessary due to the multiple advantages of designing around LLMs instead of training LLMs themselves.
I’ve offered a few ideas for future methods that tune compound AI system hyperparameters similar to how we tune standard ML models through libraries like GridSearchCV. I’m excited to see how enterprises adopt LLMs in their specific domains, and for innovations in this area!