
An Introduction to Natural Language Processing

Photo credit: Alina Grubnyak
With recent AI advances like ChatGPT, this article offers a 30,000 foot view on the most important breakthroughs in natural language processing and their impacts
Key Takeaways
In 1966, building on theory from linguists including Noam Chomsky, computer scientist Dr. Joseph Weizenbaum developed the first computer program to have a rules-based conversation, a key precursor to natural language processing.
Not until the 2010s did the development of neural networks and modern computational capabilities enable machines to be trained on languages using large amounts of data.
But this remained computationally expensive until the emergence of Word2vec in 2013. The application of neural networks with embedded dimensionality to natural language processing greatly reduced the cost.
A major breakthrough came with advancements in transformers or large language models trained on large corpuses including Wikipedia articles and books. These models sought to actually understand language as opposed to previous iterations that focused on performing natural language processing tasks.
From here, ChatGPT emerges as an impressive feat of production ready large language models that can be used out of the box on multiple generative tasks. Its innovation is not so much the model architecture or training architecture, but more about the scale of data labeling and prompting.
Grammar and Machines
In 1957, a struggling linguistics graduate wrote a revolutionary book with a revolutionary premise: by understanding the rules behind grammar, it is possible to predict all grammatical sentences of any language. The author was Noam Chomsky, and the book - Syntactic Structures. The seeds were planted in linguistics and other fields that machines could learn language. After all - what are machines good for, if not following complex rules?
Chomsky proposed a hierarchy of grammars where sentences could be represented as a tree. In particular, Chomsky imagined a generative parse tree where the sentence is divided into a noun phrase (subject), and a verb phrase which includes the object. In the example below, the sentence “John hit the ball” consists of a noun phrase (“the ball”) which in turn is contained by a verb phrase (“hit the ball”).
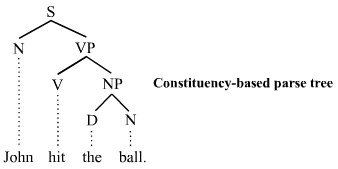
A generative parse tree: the sentence is divided into a noun phrase (subject), and a verb phrase which includes the object. This is in contrast to structural and functional grammar which consider the subject and object as equal constituents (Tjo3ya).
In 1966, as the intersection between language and machines started shifting towards computer science, a breakthrough was made. Dr. Joseph Weizenbaum at MIT made a computer program that could act as a psychotherapist and have conversations like:

If you notice, the responses look like a repetition of the sentence by the patient. This is because ELIZA was based on a set of certain rules given by its creator. This is an example of grammatical rules governing language being applied to a conversation. For example, if the patient used a word that conveys similarity such as “like/alike” then ELIZA would respond with some variation of “in what way?”
Neural Networks in Language
While many people were convinced ELIZA was intelligent and “understood” them, it was essentially a rule-based system making simple decisions based on inputs. But, in the early 2010’s, there were a series of breakthroughs involving neural networks and modern computational capabilities that unlocked the potential for machines to learn languages by training them on huge amounts of text data.
Now, let’s first answer a fundamental question: what are neural networks? It would be quite naïve to summarize a complex concept in just a paragraph, but it turns out that the essence of neural networks is quite straightforward and lies in high school algebra. The idea is that if you have a bunch of inputs (x1, x2, x3,…), then through a series of matrix multiplications (green arrows) these can be transformed to an intermediate state (a1, a2, a3, a4,…). After a non-linear transformation (maybe a step function or logistic function) followed by more matrix operations, this can ultimately yield a single number (y) which is either 0 or 1.

A simple neural network | Skanda Vivek
Why is this important? Well, the 0 or 1 could be mapped to various useful metrics. One example is sentiment analysis: where 0 could represent an unhappy sentiment (i.e., a negative review) or a happy sentiment (i.e., a positive review). And yes - these concepts can be extended to a larger number of outputs - 0, 1, 2, etc. which could represent a range of sentiments, or something else.
But you might ask - what do the x’s represent? You could think that each x represents an individual word and thus by knowing a word’s relative position you could map a sentence of say 10 words to a vector (i.e., a quantity or list of numbers) of x with length 10, while each x has a unique number. But there are two problems here:
For vectors, distance is important. What I mean is that let’s say you assign numbers to words based on their position in the dictionary. “Aardvark” is assigned a value of 1, and apple soon after, etc., The problem with this is that distance here is a meaningless concept and could highly confuse neural networks. This could bias neural networks to associate reviews containing more words starting with the letter A as positive or vice versa.
It is computationally expensive to have a dimensionality the same as the size of the English vocabulary. With hundreds of thousands of words in the English language, it is extremely expensive to assign a dimensionality the same as vocabulary.
In 2013, another innovation in neural networks called Word2vec solves the above problem by using a neural network to embed the dimensionality into 100-1000. Thus, each word now has a dimensionality of hundreds rather than hundreds of thousands - making the use of neural networks for NLP tasks much more accessible.
Here are some important tasks for Natural Language Processing (NLP):
Sentiment analysis
Text generation
Question answering
Entity extraction
Language Translation
These are only a few representative tasks and over the years as NLP advances, we shall see how this list of tasks expands.
For many tasks like language translation, the traditional neural network is inadequate. Researchers came up with a way to consider the history of preceding words using recurrent neural networks (RNNs). The idea behind RNNs is that each “cell” - which is a neural network - takes into account not just the current word, but the output from the previous history of words. This, in turn, gives relevant context for translation i.e., think about how while reading a sentence, starting from the middle might make no sense so it is best to start from the beginning.

Ex-Tesla AI director Andrej Karapathy has a minimal implementation of an RNN in python using only basic math in ~100 lines of code!
Enter Transformers
In 2017, there was another revolutionary idea in NLP. In the paper “Attention is all you need”, Vaswani et al. detail how training a model to attend to certain parts of a sentence does a much better job than recurrence. The idea is intuitive when considering this analogy: glancing at an entire sentence while translating it seems a better idea than manually going word by word during the translation - in which case you might forget some of the previous parts once you’re half-way through the translation. Transformer architectures have taken the NLP world to the next level. So far, the bigger the model and more the training data, the better the performance.
I won’t go into the details of transformers in this post but transformer models are called large language models (LLMs) for a reason; they are trained on large corpuses including Wikipedia articles and books. Language models are trained to understand languages, rather than perform specific NLP tasks right at the beginning. For example, the GPT-2 model was trained to predict the next word, given all the previous words in some text. Interestingly, such general language models perform better than the previous state-of-the-art on specific tasks downstream.

Enter ChatGPT
Recently, ChatGPT by OpenAI has taken the NLP world by storm. You can ask this chatbot any question and it responds like an expert. See this example below, where ChatGPT can give recipes in multiple languages.

Not just that, ChatGPT has all sorts of clever use cases like extracting information from text, checking code, and helping in numerous writing tasks like storyboarding. While there has been some recent criticism of the attention ChatGPT is getting, there is no question that it is a major improvement from previous algorithms.
To illustrate this, in the example below, I ask ChatGPT and the state-of-the art Flan-T5 LLM from Google (which came out December 2022) a trick question about an article to try to elicit a “false positive,” a common problem in language models whereby LLMs give answers even if there is no answer in the document.

{kind=link}
Google’s Flan-T5 LLM gives a totally wrong answer while ChatGPT makes me feel stupid for asking such a silly question.
If you dig into where the innovation lies for ChatGPT – it is not so much the model architecture or training architecture – but more the scale of data labeling and prompting. That is to say ChatGPT was trained on huge amounts of data. Also it learned through what is called "reinforcement learning with human feedback" where it can understand feedback given by moderators (which is a big step in large language model training). Basically, if ChatGPT gives an answer to a question, the human in the loop can say - that's not quite right, can you frame the answer this other way? And ChatGPT learns from such feedback.
From an industry perspective, the current implementation of OpenAI makes a world of difference as you can take the model as is and ship it out as the core engine of an NLP product for customers, (if OpenAI releases a reasonable priced API, with good enough latency) with some spot checks on how the model is doing.
Closing Thoughts
This was a whirlwind tour of NLP achievements over the years. Along with classic NLP tasks, recent NLP advancements have transformed the way we think about AI and NLP. The number of NLP applications continues to grow.
We are impacted by this everyday. While searching for items on Google, for example, summaries of answers returned are the outputs of transformer models. The company Hugging Face is on a mission to make state of the art transformer NLP models public. Many organizations are leveraging Hugging Face implementations to transform businesses. The incredible advancement in reliability of the “out of the box” ChatGPT model across any language related task you can imagine is a gamechanger in itself and will save countless hours of human effort once ChatGPT products become production ready.